다음 주제에 필요한 개념이기에 먼저 설명을 하고 가겠습니다.
다음 주제로 할 부분은 저희가 이전에 1~3주차에서 영화 관련 웹페이지를 만들었는데요. 1주차에는 형태를 잡고, 2,3주차에는 영화 API를 이용해서 불러와서 넣는 방식을 보여드렸습니다. 이번에는 OpenAPI가 아닌 영화 페이지에서 그 값을 받아와 넣어가지고 하는 작업을 하려고 하는데 이때 필요한 개념이라고 보시면 됩니다.
영화에서 OpenAPI를 가져왔을때 보였던 모습은 이 모습입니다.

사실 포스터, 제목, 설명 이 부분들은 또 각각의 코드로 나눠져 있습니다.
심지어 카카오톡에서 링크를 보내게되면 뜨는 형태가 3가지가 있죠.
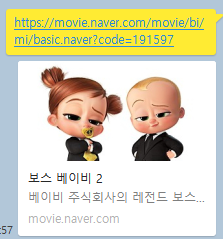
여기서도 똑같이 사진, 제목, 설명이 들어가게 됩니다. 궁금하신 분들은 밑에 링크를 남겨놓을테니 복사해서 한번 카톡에 넣어보시기 바랍니다.
https://movie.naver.com/movie/bi/mi/basic.naver?code=191597이제 저 부분을 가져오기 위해 기본 준비를 해보겠습니다. 복사해서 붙여 넣을수 있도록 코드로 넣겠습니다.
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/bi/mi/basic.naver?code=191597'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
기본 코드에 더 추가적인 코드를 하기에 앞서 3가지(사진, 이름, 설명) 이 어디에 나와있는지를 한번 보겠습니다.
위에 올려드린 네이버영화 들어가셔서 오른쪽 마우스 클릭 - 검사 - body부분이 아닌 head부분 - 펼치기 하시면
다음과 같은 코드들이 있습니다.

이 코드들이 실제 사진, 이름, 설명을 보여주기 위해 사용 되었던 부분인 Meta tag라고 합니다.
이 코드들을 가져와서 py파일에 한번 출력해보도록 하겠습니다. 저희가 필요한 부분은 og:image, og:title, og:description 부분이므로 그 부분만 사용하겠습니다.
혹시나 코딩을 하실때 사용했던 코드들이 기억이 안나시면 다음 링크에 bs4 soup 형태인 기본 코드들을 보시면 되겠습니다.
https://iceflower.tistory.com/15?category=1045145
웹 스크래핑(크롤링)
이번에는 웹 스크래핑(크롤링)을 한번 해보려고 합니다. 웹 스크래핑을 하기 위해서는 먼저 필요한 패키지가 있으므로 다운받으러 가봅시다. request 패키지 : 파일 - 설정 - 프로젝트 - Python 인터
iceflower.tistory.com
이제 만든 코드들을 가져와 설명하겠습니다.

코드를 보시면 각각의 필요한 상위 태그명들을 가져오고 그 태그명에서 필요한 content들을 변수에 대입한 후 출력하는 코드를 작성했습니다. 그 결과를 보시면 다음과 같습니다.
( 참고로 py파일 자체에서는 이미지를 확인할 수 없기때문에 이미지 주소로 나타납니다. )

이제 이 내용을 가지고 OpenAPI가 따로 없어서 못 붙이신 분들을 위해 붙일수 있게 되었습니다.
다음 내용에서 확인하시죠.
'웹개발 개발일지 > 4주차' 카테고리의 다른 글
| 팬명록 기록 추가하기 (0) | 2022.09.02 |
|---|---|
| 영화 사진, 제목, 설명을 가져오는 주제로 GET, POST 이용하기 (0) | 2022.09.02 |
| 화성 땅 공동 구매라는 주제로 GET, POST 이용하기 (0) | 2022.09.02 |
| 기본적인 Flask를 다뤄보기 (0) | 2022.09.01 |
| 새로운 주제에 앞서 Flask! (1) | 2022.09.01 |



