728x90
이번에는 웹 스크래핑(크롤링)을 한번 해보려고 합니다.
웹 스크래핑을 하기 위해서는 먼저 필요한 패키지가 있으므로 다운받으러 가봅시다.
- request 패키지 : 파일 - 설정 - 프로젝트 - Python 인터프리터 - 더하기 버튼 클릭 - request
- bs4 패키지 : 파일 - 설정 - 프로젝트 - Python 인터프리터 - 더하기 버튼 클릭 - bs4
이 두개의 패키지 설치를 완료 하셨으면 크롤링 기본 세팅을 보여드리겠습니다.
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################위의 코드를 그대로 가져가서 붙여 넣기 하시면되는데 data = requests.get 부분의 링크는 네이버 영화 랭킹 URL 이므로 다른걸로 바꿔서 도전해보고 싶으시면 다른 URL로 변경하시면 됩니다.
header 부분과 soup 부분은 부트스트랩과 폰트때 링크 가져오는것 처럼 기본적으로 가져오는 코드라 생각하시면 됩니다. 먼저 네이버 영화 랭크 페이지에 가서 무엇을 가져올지 확인해보겠습니다.
위의 코드는 이전 랭킹이라 최신 랭킹으로 보고자 하시는 분은

https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=2022083
랭킹 : 네이버 영화
영화, 영화인, 예매, 박스오피스 랭킹 정보 제공
movie.naver.com
들어가시면 최신 링크를 확인 하실수 있습니다.
사진을 보니 순위, 영화제목, 평점을 가져올 수 있을거 같네요. 3개를 가져오기 전에 bs4에서 사용되는 기본적인 부분을 먼저 설명 드릴려고 합니다.
이렇게만 보면 약간 어려울 수 있으니 예를 들어 드리겠습니다.
영화 랭킹 페이지를 가셔서 영화명(전 1순위 영화명에 커서를 두겠습니다.) 에다 커서를 놓고 오른쪽 버튼을 누르시고 검사를 누르시면
이런 비슷한 화면의 콘솔 창이 떠 있을겁니다. 여기서 파란색이 의미하는 부분이 영화명을 만드는데 사용한 자리라고 보시면 됩니다. html창이기 때문에 꽤 익숙하죠?
저 상태에서 파란 줄에 오른쪽 버튼을 누르시고 Copy - Copy Selector를 누르신 후 py파일에 붙여넣어보시면
이런 형태가 나오시는걸 보실 수 있습니다. 추가적으로 2,3,4 위도 한번 보겠습니다.
이렇게 보니 한 부분 빼고 엄청 비슷하지 않나요? 가운에 tr:nth-child(숫자)에서 숫자 부분만 바뀌고 나머지 부분은 다 같다는 걸 보실 수있습니다. 그럼 상위와 하위 태그명을 나눠보겠습니다.
상위 태그는 겹치는 부분 중 앞 부분이므로 # old_content > table > tbody > tr 까지 이고
하위 태그는 겹치는 부분 중 뒷 부분이므로 td.title > div > a 입니다.
이걸 가지고 제목을 가져오는 코드를 작성해보면 다음과 같습니다.
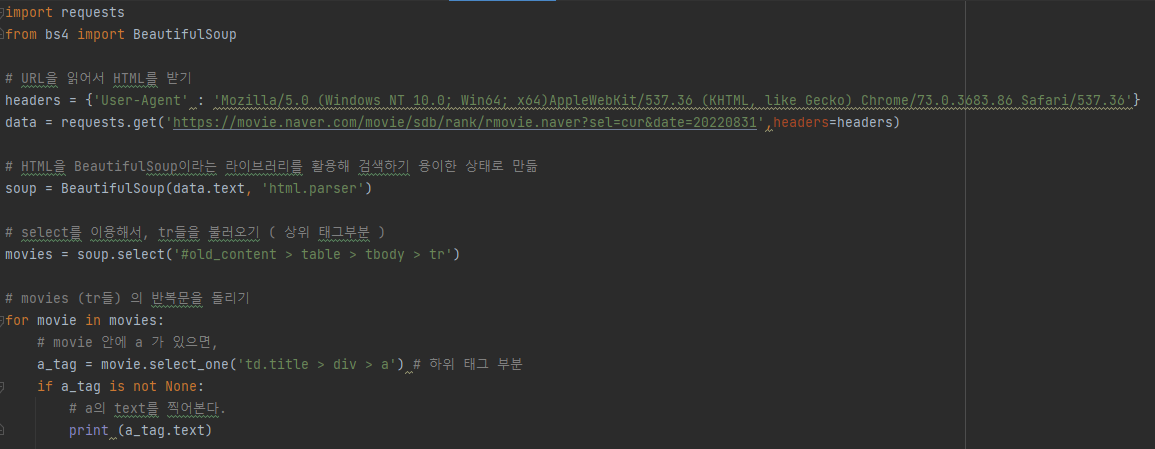
상위 부분을 정하는 변수는 movies라 하고 그 movies를 반복문 돌리면서 값을 출력하는 형태입니다. a_tag is not None 부분은 가끔 영화제목이 없는 부분이 같이 출력될 수 있기 때문에 그 부분을 제외하고 영화명만 출력하기 위해서 조건문을 걸어 놓았습니다.
저 코드의 결과를 보여드리면 다음과 같습니다.

제목을 통해서 어떤 방식으로 값을 가져와야하는지 체크를 했기때문에 추가적으로 순위와 평점을 같이 가져와 보겠습니다. 먼저 한번 도전해보시고 결과를 보시면 더 좋습니다.
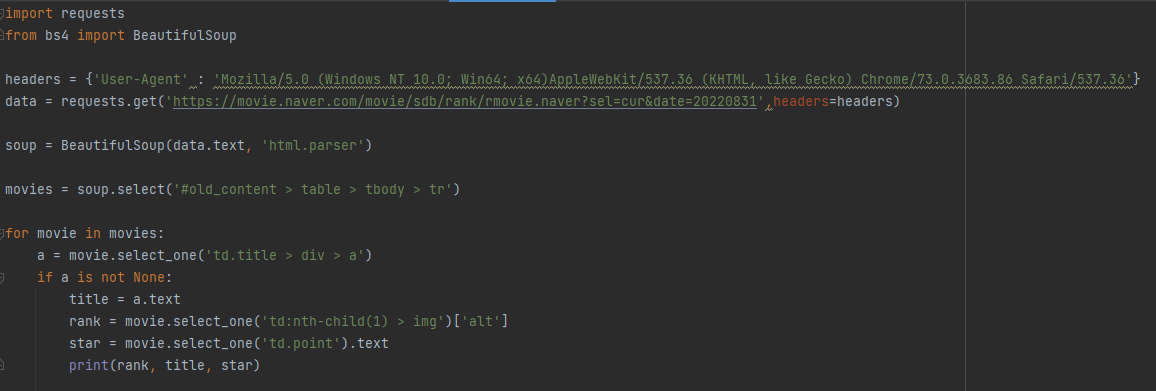
제목과 똑같은 방식대로 별점, 순위도 똑같이 겹치는 부분을 찾게 되면 위의 코드 처럼 작성할 수 있습니다.
제목과, 별점은 text값이기 때문에 text를 붙여줬지만 순위 값은 다시 콘솔에서 보게되면

alt부분이 순위를 의미하기때문에 alt를 가져와야해서 코드를 위와 같이 작성했습니다.
코드의 결과는 다음과 같습니다.

728x90
'웹개발 개발일지 > 3주차' 카테고리의 다른 글
| 지니 뮤직 크롤링하기 (0) | 2022.09.01 |
|---|---|
| DB 설명 및 사용 (1) | 2022.09.01 |
| 패키지 설치 및 패키치를 이용한 간단한 코드 (0) | 2022.09.01 |
| DB를 하기에 앞서.. (0) | 2022.08.31 |



